
This is part of an open-ended series on the relationship between the AI hype, corporate interests, and scientific publishing through the lens of articles published on Nature.com. For the previous one, click here.
Nature's Scientific Reports recently published a study titled "AI-generated poetry is indistinguishable from human-written poetry and is rated more favorably." For those of us familiar with mainstream journalists' AI-hype death drive, the title is obviously media-bait, and many outlets have dutifully taken it, including The Washington Post and The Guardian. More interesting for us, however, it presents us with a fascinating case study in the AI hype's underlying ideology and its relationship with invisible, alienated labor.
Like so many of these papers, they back a sweeping claim with a simple setup and some performative but ultimately meaningless statistics that exist only to make peer-reviewers feel safe. In this case, they picked 10 famous poets1 and had ChatGPT generate some poems in each of their styles. They then asked two groups of participants to either rank the poems or assess them on different qualitative traits. Here's what they found, from their "Discussion" section (emphasis added):
Contrary to what earlier studies reported, people now appear unable to reliably distinguish human-out-of-the-loop AI-generated poetry from human-authored poetry written by well-known poets. In fact, the “more human than human” phenomenon discovered in other domains of generative AI is also present in the domain of poetry: non-expert participants are more likely to judge an AI-generated poem to be human-authored than a poem that actually is human-authored. These findings signal a leap forward in the power of generative AI [editor's note: 🙄]: poetry had previously been one of the few domains in which generative AI models had not reached the level of indistinguishability in human-out-of-the-loop paradigms.
I'm not sure what that last sentence is supposed to mean without some sort of enumeration of all the domains. They provide 7 citations for 3 domains: visual art, pictures of faces, and text.2 That seems like too few for that claim to mean anything, but surely they can't mean all the domains, because generative AI still cannot do anything in the material world except burn energy and guzzle water. Do they mean all the domains for which there exists generative AI? It's difficult to imagine a definition that makes that statement both meaningful and true but doesn't at least somewhat beg the question. We also have this "human-out-of-the-loop" paradigm, which we'll explore at some length later.
For now, zooming out, this paper makes two sorts of claims: the first about the quality of ChatGPT's poetry, and the second about how humans perceive poetry that they believe is AI-generated. For this first set, I will quote briefly from a breakdown by Ernest Davis, titled "ChatGPT's Poetry is Incompetent and Banal: A Discussion of (Porter and Machery, 2024):"
I urge anyone who reads of these experiments and concludes from their results that ChatGPT will soon put poets out of business or that ChatGPT is now so skillful a poet that only an expert can tell it from human poets, to download the collection of poems used in the experiment and judge for themselves[...] Two things leap out in the collection. The first is the staggering banality of the poems that ChatGPT has produced. In the whole fifty poems, there is not a single thought, or metaphor, or phrase that is to any degree original or interesting.
Among many insights, Davis (politely) points out that one of the AI-generated Chaucer poems is just "the opening of the Prologue to the Canterbury Tales." That's literally the very beginning of his most famous text, suggesting, as I will soon argue, that what the authors call "indistinguishability" is a property not of the AI-poetry, but of the authors themselves. Davis goes on to point out that, actually, "contrary to the title," the poems are trivially distinguishable using one single metric:
The simple rule that a poem was written by ChatGPT if it is either a Shakesperian sonnet, a single couplet, or consists of four-stanza verses and follows an AABB or ABAB rhyme scheme will have an accuracy of 87.8% both on the ChatGPT poems and 88% on the human-authored poems
I have nothing to add to Davis's critique of the first half of the results. It's only ~6 pages of text, and, after reading it, I am thoroughly convinced that the researchers spent almost no time actually reading any of this poetry. For further discussion on that first set of claims, I refer you to Davis's writing. Instead, I want to critique the paper's methodology, then examine that second set of claims in light of that critique.
This study used Prolific to recruit its participants, one of these "Mechanical Turk"-style "get paid by the task" services, on which you can "[e]arn a minimum of $8.00 an hour per task" to "[c]ollaborate with the world's top AI researchers, business leaders, and academics—all using Prolific to learn about human behavior." For those of you unfamiliar, it's like Door Dash, except AI researchers order data from random exploited gig workers instead of food.
The authors of this study dedicate a section to doing a bunch of statistics on participants' previous experience with poetry, but do not discuss the material conditions under which this data was generated. Prolific doesn't have too much publicly available information, so I forced The Luddite's unpaid intern to sign up and investigate.
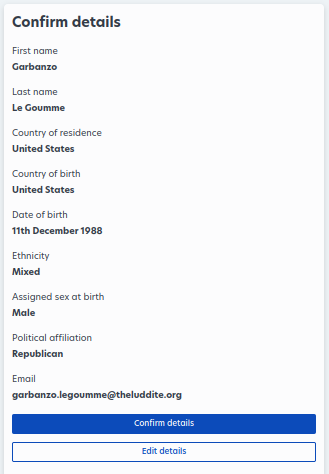
I was disappointed to discover that there is a waitlist to join, but Garbanzo must be a wonderful candidate, because he was approved after 11 minutes. I suspect that this is because Garbanzo claims to be an English speaker in the US, and/or because part of their marketing is that they generate only the highest quality data from vetted participants. Making it seem like they have a waitlist, even if they don't, is to their advantage. This is a classic marketing gimmick.
![Screenshot of an inbox that contains two emails from Prolific. The first is 'Please confirm your email address [...] Thanks for joining our waitlist' and the second reads 'The wait is over, join Prolific and start earning!' Both email previews, below the subject, have the text {{subject}} which I reference in the image caption](/img/ai-poetry/prolific-email.png)
To get started, you have to do a short onboarding/training and have your ID verified. Garbanzo, unfortunately, has no ID verification, but here is what the onboarding questions looked like, which I assume give us a rough sense for the kind of thing that Prolific users are doing:
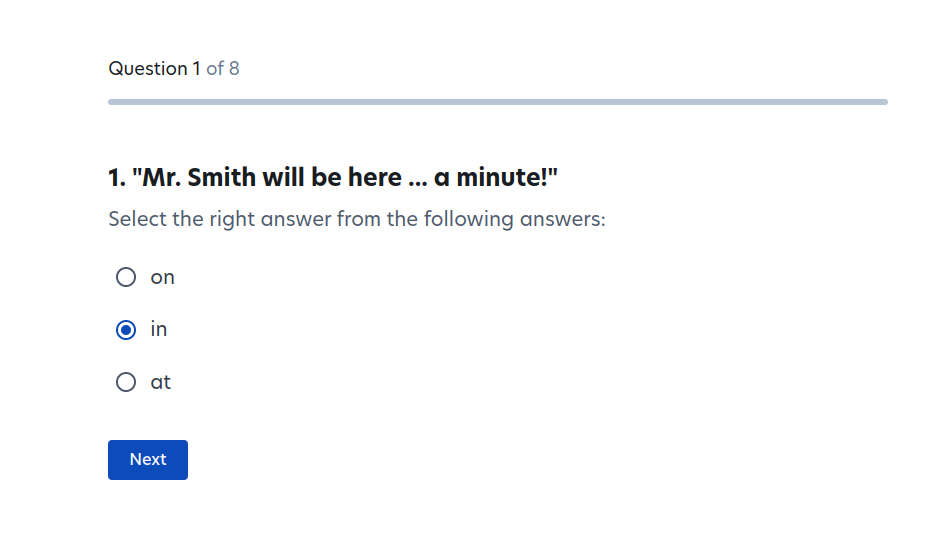
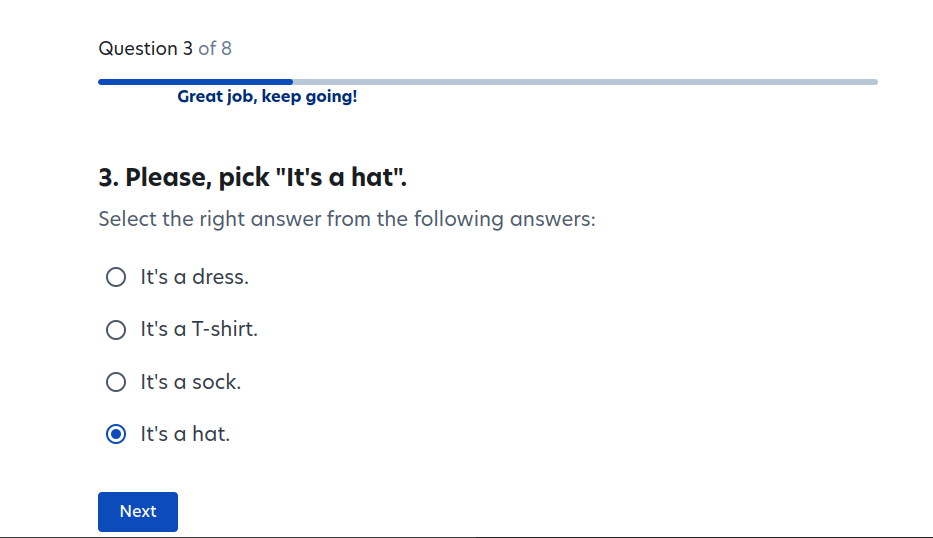
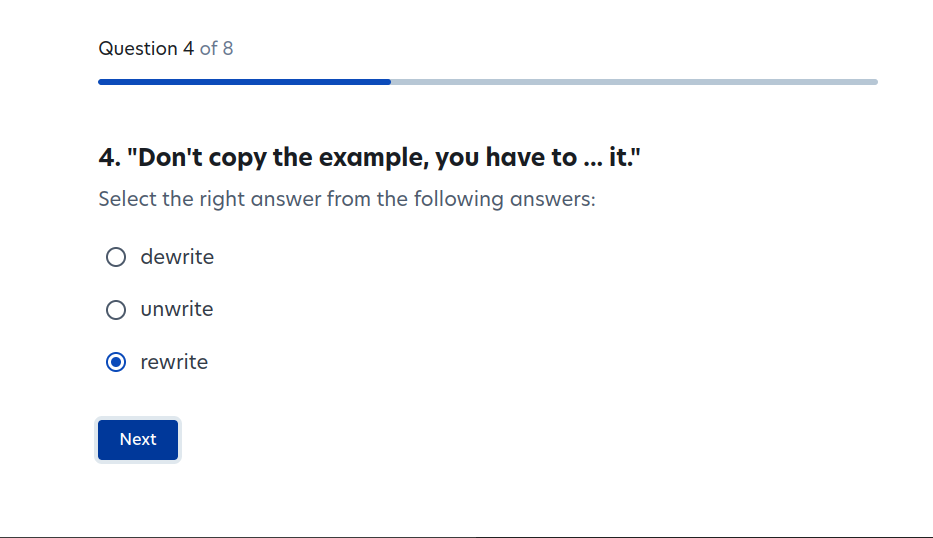
I argue that the results of this experiment are trivial to predict from the material conditions of participating: If you (under)pay participants by the task, such that they get paid more if they do tasks faster, then barrage them with mind-numbing tasks, they obviously prefer ChatGPT-generated poetry to human-generated poetry. People in a hurry prefer convenient things. The authors presumably already understand this, otherwise they'd be very confused by such mundane phenomena as instant coffee. In this case, however, AI researchers have become so accustomed to the legions of underpaid workers manually creating their data that they no longer consider the conditions of this work.
Still, that doesn't completely explain this particular oversight. Consider doing this same experiment, but, instead of poetry, it's literally anything STEM, and, when our criminally underpaid participants preferred ChatGPT, we gleefully write a paper titled "AI-generated physics is indistinguishable from human-written physics." It's unimaginable that such a paper would pass peer-review in any scientific journal.
Apologists for this kind research might object here, saying that this is a facile comparison because physics papers can't be evaluated in the same way as poetry, but that is precisely my point: Just like we don't do randomized drug trials for physics experiments, we can't just impose arbitrary ways of measuring poetry. Ordering some data about poetry from an app is not engaging with poetry on its own terms, but contorting it into an unrecognizable form.
We use these findings to offer a partial explanation of the "more human than human" phenomenon: non-expert poetry readers prefer the more accessible AI-generated poetry, which communicate emotions, ideas, and themes in more direct and easy-to-understand language, but expect AI-generated poetry to be worse; they therefore mistakenly interpret their own preference for a poem as evidence that it is human-written.
To think that this reflects anything about expertise or innate preferences is condescending and absurd, so I offer an alternative explanation: The mistake participants are making is that, while quickly scanning the poem, they are relying exclusively on the single most readily-apparent heuristic upon reading any text: whether they understood it. The participants basically told them as much:
In our discrimination study, participants use variations of the phrase "doesn't make sense" for human-authored poems more often than they do for AI-generated poems when explaining their discrimination responses (144 explanations vs. 29 explanations).
Instead of mistakenly interpreting their preference as evidence that it is human-written, much more likely, I argue, is that participants are simply using the same heuristic for a poem being preferable and human-written: They both prefer easy-to-read things and assume that machines are bad at producing them. These people presumably spend hours and hours a day correcting the dumb crap that AI models get wrong, or labeling things that are painfully obvious to a human for the benefit of AI researchers. Of course they think that computers are bad at poetry. Concluding that any of this can be generalized is just reifying the conditions of participation, with the exception of what I think is their most plausible claim:
Ratings of overall quality of the poems are lower when participants are told the poem is generated by AI than when told the poem is written by a human poet [...] confirming earlier findings that participants are biased against AI authorship.
In this case, I suspect that they are right, because this is trivial to predict from first principles: People are biased against AI poetry the way that we are biased against robotic hugs. If you tell someone that a hug wasn't actually from a person, they like it less. People prefer human poetry because it is human, by which I mean that it is quintessentially human. Consider the power of art to so completely communicate emotions as to trigger them. This is a miraculous and almost universal human experience. We are social beings, but, tragically, the richest part of our inner lives are forever trapped inside ourselves, the only place that no one else can ever be. For me, poetry, music, art, etc. are attempts to reach across not just time and space, but to breach this ultimately inescapable solitude. They are rebellions against our fundamental loneliness, maybe even temporary reprieves. To attempt to study this by relying on the most alienated possible labor to manufacture data is parody. It tells us nothing about poetry as such, but reveals instead an underlying ideology that is arrogant, inflexible, and impoverished.
This paper is the perfect encapsulation of two remarkably consistent themes present in the dozens of AI-hype-media-bait papers that I've covered, whether they got full posts, like in this series, or just a few toots on Mastodon. In my very first post about AI research, from well over a year ago, I looked at a handful of popular news stories about how AI is coming for your job, then read the actual papers behind them. This was my conclusion:
These so-called studies are purposefully, almost explicitly designed to reach the result that workers are dispensable. Even when they obviously demonstrate exactly the opposite, the researchers and the media still dutifully report that we workers are replaceable, because AI is coming for our jobs. It is, whether consciously or not, capitalist propaganda that exists to discipline labor, to convince us that we should be grateful for what we have, and to force us to think twice before demanding more.
This paper displays a very similar pathology, but, as Davis points out, almost no one actually makes a living doing poetry. So why automate poetry?
The first clue can be found in our second theme: AI researchers continuously omit all the human labor when telling these stories. This includes not just the low-paid grunt labor, but the researchers themselves. Returning again to that first post on AI research, in the very first example, the researchers claimed that ChatGPT could do every job at a tech company all by itself. The paper then went on to describe all the labor that they had to do to even get the code to run, much of which didn't. In another previous example, this paper claimed that "GPT-4 ranked higher than the majority of physicians" in various medical exams, but, hidden in the body, was this damning admission:
Because GPT models cannot interpret images, questions including imaging analysis, such as those related to ultrasound, electrocardiography, x-ray, magnetic resonance, computed tomography, and positron emission tomography/computed tomography imaging, were excluded.
This lays bare the absurdity of the so-called "human-out-of-the-loop" paradigm: Literally everything that ChatGPT does has humans in the loop. A human types the prompt and pastes the response, then they paste it into Prolific on the computer that they carry into work every day and manually plug into the wall. The only step that the LLM does is generate the text. In the case of that Chaucer poem, it simply plagiarized the work of a human, but, even when it doesn't, in this experimental setup, it doesn't have an original style, but relies on the pre-existing styles of famous poets. In other words, not only did they explicitly put 10 poets "in the loop," but, loop or no loop, this methodology is incapable of proving that AI is "indistinguishable from human-written poetry" because human poets are expected to innovate on style.
This paradigm is an ideologically-motivated work of fiction, based on a true story in the most Hollywood sense. It is the difference between, say, remote-controlled cars and self-driving ones. AI cannot function without consistent human intervention at all scales, from the lowliest data-laborers to the researchers themselves. This is in fundamental tension with the AI hype's ideology, so they simply omit the human labor from the story that they tell us and, more importantly, themselves.
Finally returning to our little puzzle, then, the second clue is the choice of poetry itself, since it's the most human thing there is. Instead of disciplining labor with the threat of machines, studies like this attempt to discipline people for not being the machines they were promised but still rely on. The choice of poetry is the choice of someone lashing out in the moment, trying to say whatever is most hurtful to the perceived object of their frustration. It is the ultimate irony to put statistics on an attempt to resolve ideological dissonance and pass it off as cold, rational science.
1. From the paper: "Geoffrey Chaucer (1340s-1400), William Shakespeare (1564-1616), Samuel Butler (1613-1680), Lord Byron (1788-1824), Walt Whitman (1819-1892), Emily Dickinson (1830-1886), T.S. Eliot (1888-1965), Allen Ginsberg (1926-1997), Sylvia Plath (1932-1963), and Dorothea Lasky (1978- )"
2. Is AI-generated poetry really a different domain from text? LLMs are exactly one domain, generating plausible text. That is literally all that they do. For further reading on this topic, consider our forthcoming paper: Tokens, the oft-overlooked appetizer: large language models (LLMs), the distributional hypothesis (DH), and meaning.